





Eric Wall published this post at Medium. Follow him on Twitter for insight and commentary.
So, Hedera Hashgraph is launching on September 16. It’s a 3rd generation DLT and it can do 10,000+ TPS!

Amazing, right?
Yeah! Or wait, I forgot something.
Because I hold huge bags of bitcoin (or was it BCH? or Qtum? I lose track) that I’m apparently for some magical reason unable to sell, I don’t have any alternative but to conjure up and spread FUD theories about Hedera Hashgraph. Because I couldn’t just do the simple thing and invest in it. That would break all the laws of the universe. /s
Unpacking the Hedera Hashgraph FUD

In this post, I’m going to try to tackle one simple question: How does Hedera Hashgraph supposedly achieve 10,000+ TPS?
First, we need to disarm some myths about how TPS works in general.
The relationship between Proof-of-Work and low TPS
There’s this prevailing idea among cryptocurrency investors that the inefficiencies of the Bitcoin blockchain are in its Proof-of-Work system, and if someone just invented a faster consensus algorithm, then DLTs could all of a sudden process hundreds of thousands or millions of transactions per second.
I’m guessing this theory comes from observing Bitcoin as a system where miners spit out ~1.2 MB (current average) of blocks every 10 minutes, sort of like train carriages coming to your computer from the mining pools.
Understanding block propagation (simplified)

This was a good mental model for when you were first grokking bitcoin, but it creates the perception that miners are the ones throttling the amount of data you receive. Not only is that an incorrect way to understand the system, but it’s also not how it works anymore even technically.
Since sometime 2016, Bitcoin Core implements BIP152, also known as “Compact Blocks” (if you’ve heard anything about the FIBRE Network, the compression technique is similar). If you understand how BIP152 works, you understand that the correct way to view the Bitcoin network is more something like this:

Miners don’t actually broadcast blocks of transactions anymore, they just provide you with the minimal amount of info you need in order to sort a batch of transactions you’ve already received from the network together with a 80-byte header that satisfies the PoW requirements. This PoW is ridiculously easy to validate; you can validate all Bitcoin’s 592,926 PoWs in less than a second on a laptop.
To organize a data blob of 1.2 MB of transactions on your computer into a Bitcoin block, you’ll need something around 15000 bytes to sort it (6 bytes per transaction shortID). That’s 1.25% overhead. That’s what the tiny train carriage in the image above represents. It involves no advanced signature operations or things that are going to drain resources from your machine. And you receive it in parallel to the overall transaction stream.
Now, if you want to point the finger at the mining process and say that that is the thing that’s slowing down the system, you’re essentially saying that you can speed the system up by reducing the size of that tiny train carriage. You’re saying something like “we’ve found a way to reduce that 1.25% overhead to 0.75%!”. But we wouldn’t even notice such a change.
So if it isn’t the miners who’re limiting the numbers of transactions I can write onto my blockchain, who’s doing it?
You are. You are running code on your Bitcoin node that says “I will only accept updates coming from miners that attempt to sort at most 4 MB of data (SegWit theoretical maximum), otherwise I will reject the update.”
So, can’t I just increase this limit? What’s stopping me?
You can’t change it in Bitcoin without forking yourself off the network. This limit is a consensus rule. But of course, it still possible to do it, like Bitcoin Cash (32 MB blocks = 100+ TPS) and Bitcoin SV (128 MB blocks = 400+ TPS) have done.
But the computers and their connections in the network don’t go any faster just because you increase the upper bounds of the application. It just means that it will be harder for some nodes to keep up, and the decentralization of the system will start to fall apart. BCH and BSV still consider this a trade-off worth doing.
You should now understand that it’s not the mining nor Proof-of-Work that gets in the way of reaching high TPS counts on the mainnet.
Here’s from the Hedera Hashgraph whitepaper:

As you can see, when they talk about their throughput, not even they are talking about how fast their consensus algorithm is. So let’s put this myth to rest, please.
But Hashgraph’s consensus algorithm is super fas-
No. It doesn’t matter if Hashgraph’s consensus algorithm is so fast that it all just happens all automagically. All you’re talking about is reducing the size of that tiny train carriage. Even if you eliminate it completely, you have barely done nothing to improve the performance of the system.
Quick note on speed: There are two ways DLTs can go “faster”.

There’s the TPS, and then there are transaction confirmation times (finality latency). That Hedera Hashgraph has quicker native finality is mostly true, but it’s also sort of debatable. I’ll just point to a few counter-examples on how you can reach hashgraph-level latency for bitcoin and other Proof-of-Work chains:
- Sidechains: You can have a consortium of nodes controlling a bitcoin multisig wallet where you deposit your coins, where >2/3 of the nodes are required to sign off on transactions made within the wallet and before they can leave the wallet. This is what Blockstream’s Liquid is (which runs on a 1 minute block time, and reaches finality at the 2nd block). You can set up something faster if you want; for example, the nodes operating the wallet could run the open-source XRP codebase and settle transactions with the same speed as Hedera Hashgraph (~4 seconds), with similar security guarantees.
- Lightning Network (L2): Lightning transactions are fast. It is a channel-capacity dependent L2 solution, but can settle transactions near-instantly, with almost the full assurance of Bitcoin’s Proof-of-Work security.
- Pre-consensus: Another way to reduce finality latency is to have mining pools come to a consensus on which transactions in the mempool to include in the next block on beforehand and orphan any miner that doesn’t follow the plan (it means they lose block reward). This is what Bitcoin Cash is planning with Avalanche (called “pre-consensus”). Avalanche reaches consensus in ~2 seconds with strong probabilistic finality.
- 0-conf: You can just accept a transaction as soon as it shows up in your mempool. This happens nearly instantly. Oh, but this is insecure you say? You’re saying while it’s true that most miners honor the first-seen rule there are some pools out there replacing transactions that could end up losing you your money? So… you’re saying it doesn’t matter how fast the transactions are, but how difficult it is to reverse such a transaction and how harsh the punishments are for the actors trying to do it? I agree 🙂
Hedera Hashgraph vs PoW inefficiency
Before I leave this part, I do want to talk quickly about how efficient Hashgraph’s consensus algorithm actually is compared to PoW in terms of how much data is propagated and needed for validation. If you’re not interested in this, you can skip to the next heading.

So Hedera Hashgraph doesn’t have blocks, but it does have messages. This is what the blue circle in the image above depicts — these are constantly sent around to each other by the nodes in the system. These messages contain one or several transactions, just like blocks do. And the transactions in these messages are all signed by their respective senders. But the senders are different from the nodes. Senders are the typical people outside of the network who just want to get their transaction confirmed, and they deliver it to these selected Hedera nodes (Alice, Bob, Carol etc.) who are responsible for including it in the hashgraph. And that’s how the transactions end up in messages (tiny blocks) that the nodes then circulate with each other.
Now, Hashgraph has it’s own special way of reaching consensus on the transaction order, which isn’t important to this topic right now, but what you need to know is that they use a virtual voting process that is enabled by nodes doing what’s called “gossiping about gossip”. This means that when a node receives transactions, it gossips this information to its neighbors (what the transactions were), but it also gossips the identifiers of the last message it received and the last message it sent (those are the two “hashes” in the image above). You don’t need to understand why they do this, but it is what allows the system to reach unanimous consensus without voting on things.
Now, Hedera prides itself on being able to broadcast this gossip very efficiently because nodes just send identifiers and sequence numbers rather than the actual hashes which would otherwise amount to rather many bytes (see “Efficient Gossip”, p. 91, Hedera Hashgraph whitepaper), whereas when using their design it only amounts to one or two bytes per hash tops. But the real overhead in this system are not the hashes — it’s the signatures which are 64 bytes each. Remember, these signatures that each node attaches to their messages (tiny blocks) have nothing to do with the cryptocurrency transactions they contain, they are additional signatures that the nodes use to come to a trusted consensus on the transaction order. It’s a part of the Hedera voting protocol, ergo, it’s all overhead!
Now, do you remember what the PoW overhead was in the example for Bitcoin? 6 bytes per transaction + 80 byte overhead (it’s a few bytes more, but not relevant):

So this means that unless each gossiped message in Hedera contains more than 10 transactions, Hedera’s 64 byte signature overhead is already more bloating than Bitcoin in terms of how many bytes must be sent for consensus purposes. Also, this overhead contains signatures, and validating them requires doing a signature validation step on your computer.
For some frame of reference, Bitcoin artificially limits the number of signature operations (sigops) a block can contain to 20,000 to not put too much load on the computers validating the blocks. That’s 20,000 signatures per 10 minutes. That’s just 33 signatures per second. Hedera is doing far more than this for the consensus process alone. And that’s not counting Hedera’s hash identifiers and timestamps that also need to be gossiped with each message for the consensus to work.
The lesson here is that Bitcoin’s consensus process already is truly lightweight. Apart from those 6 bytes per transaction necessary to order the transactions into a block, Bitcoin only emits ~80 bytes of data every ten minutes for consensus to be reached. This is a bizarrely little amount of data, compared to Hashgraph that gossips about gossip constantly and attaches 64 bytes of signature data every time a node gossips.
So maybe Hashgraph really is a revolution in voting protocol efficiency, I really don’t know — but what I do know is that it’s got nothing on PoW, which doesn’t have to deal with votes at all.
Now to the fun stuff
Let’s re-read that sentence about throughput once again:
If the network node has enough bandwidth to download and upload a number of transactions per second, the network as a whole can handle close to that many transactions per second.
One thing that’s bound to make certain people spill their coffee is that Hashgraph is cloning Ethereum’s EVM (the engine for Ethereum transaction and smart contracts execution) so it will work with Solidity applications.
For those who have followed my Ethereum syncing thread, you’ll know I’m currently running the EVM at the capacity of what my machine is capable of at the moment. And what’s interesting is that it isn’t the bandwidth that’s the bottleneck. Actually, here’s a list of the things that are not the bottlenecks on my Ethereum node:
- Downloading all the blocks and transactions (in the right order)
- Validating the Proofs-of-Work
- The RAM
- The CPU
With only 100 KB/s utilized, my machine already has more than enough transactions buffered, waiting in a queue to be processed. But it’s the speed of the SSD that stops this transaction processing from going any faster. And my MacBook Pro 2019 has the fastest SSD a laptop can have (which is really competitive). Here’s a snippet from my Ethereum log file:

These “tx/s” (TPS) counts are from my SSD’s attempts to squeeze transactions through the EVM as fast as possible. Yet, due to inefficiencies that are inherent to the EVM and my SSD, we’re doing no more than 300 TPS. And I’ll tell you one thing that wouldn’t make this transaction processing go any faster: a hashgraph.
The reason for that is that it doesn’t address any of the bottlenecks. The only thing the hashgraph does is sort the transactions to be received by the EVM. But the problem for the EVM isn’t that it can’t receive 10,000 ordered TPS, it’s that it can’t process the transactions quickly enough even on a fast SSD. You’d only make the queue longer.
So let’s go back to this image:

How is it that Hedera Hashgraph can do 10,000+ TPS when Ethereum struggles with 12 TPS, when they’re both using the EVM?
Okay, for this answer, I don’t actually get to mention the fun stuff. This comparison is just broken because Hedera’s figure doesn’t actually have anything to do with the EVM. See here:
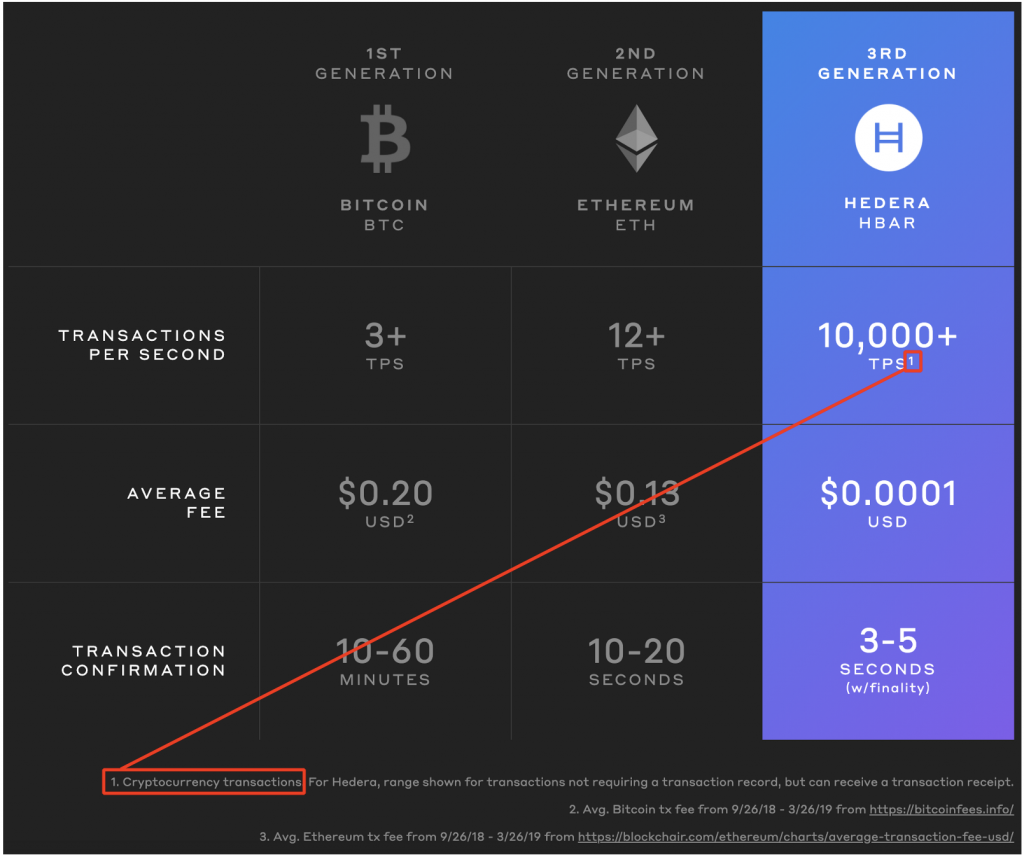
“Cryptocurrency transactions”.
So are those cryptocurrency transactions, like Ethereum cryptocurrency transactions are, executed by the EVM?
No. Let’s look at the architecture:

In Hedera Hashgraph, the cryptocurrency transactions are done by a separate service than the smart contracts. So when they’re talking about 10,000+ TPS and comparing it with Ethereum’s 12 TPS, they’re not talking about transactions that go through the EVM and can follow arbitrary smart contract logic (the whole purpose of Ethereum), it’s just talking about dumb account-to-account token transfers.

Now I’m guessing that you’re starting to get annoyed, and it’s probably me you are annoyed at. Am I saying that Hedera Hashgraph does nothing to improve scalability? That Leemon Baird and Mance Harmon are just blatantly lying about everything? That somehow this is a $6 billion project and nobody is talking about its flaws?
Of course not, this isn’t IOTA. But are you ready now to understand how Hedera Hashgraph actually achieves high TPS?
Introducing… the Consensus Service!

If you made it this long in the post, I congratulate you (not you lazy people who skipped just to the fun part :C), because this is where all the magic happens.
The Consensus Service is a service that Hedera nodes will run in parallel to everything else they’re doing. But it’s not what it sounds like. This service exposes an API that lets “normal users” access events that have happened on the hashgraph so they can learn if they’ve received a particular payment or the status of an account balance, for instance.
So basically, the Consensus Service is a set of centralized databases that you can query for information. Disappointed? Well, you shouldn’t be, because this Consensus Service actually delivers you “state proofs”! With these proofs, you can rest assured that the answer you’ve received is fully endorsed by the Hedera nodes.
Here are the different levels of responses you can get from the Consensus Service API (source):
- Response: This is just an ACK that a transaction was received. You trust the Consensus Service node you’re speaking with 100%.
- Subsequent query: This is an ACK that a transaction was included in the hashgraph. You trust the Consensus Service node you’re speaking with 100%.
- Receipt: When a transaction is included in the hashgraph, a receipt is created for 3 minutes. You can ask any Consensus Service node for this receipt and thereby get a “second opinion” to feel more confident that the transaction was actually included. You trust the Consensus Service nodes you’re speaking with 100%.
- Record:
- Record + state proof:
Wait!
W-w-w-w-wait. Just hold on there a minute. Do you remember the fineprint?

Let’s zoom in a bit. Turns out there’s more in this fineprint that we forgot to read before:

For Hedera, range shown for transactions not requiring a transaction record, but can receive a transaction receipt.
So… the 10,000+ TPS figure is without even giving the state proofs? You’re just counting how many times per second a node can claim that it received a transaction per second, but it comes with no assurances and is basically just a trusted API? Oh, wow. That’s really incredible. It really sucks that I can’t invest all my money in this right now and that it’s magically impossible for me to sell my bitcoins.
But OK, let’s continue.
- Record: A receipt but with more info, like timestamps and the results of a smart contract function call.
- Record + state proof: Here it starts to get interesting. The state proofs! So what’s in a state proof? For those of you who know how SPV proofs work in bitcoin, this is equivalent. The Hedera nodes will have signed a Merkle root, which is included along with the Merkle path, showing that a current account balance, transaction (or whatever was queried) exists within the timestamped, current state. The signatures on this Merkle root are included as well. The Hedera signatures on the Merkle root thus “proves” that the response you received was correct.
So, clever readers will now ask, okay, so I get some signatures with the response but how do I even know that the signatures are the Hedera nodes’ signatures?
Well, they’ve thought about this too. They’ll send you the whole “address book history”, which means the entire list of all Hedera nodes’ public keys and all changes to that set of public keys that were made, signed by the previous in every step. So it’s like a tiny blockchain that tracks trusted keys instead of coins.
So, now the clever reader asks, but how will I even know that the starting keys are correct? And for this question, I have to cite the Hedera blog:
No hacker would be able to fool Bob with a state proof for any corrupted state, as they would be unable to recreate the signatures and address book history that matches the known and trusted Ledger ID — this to be published by Hedera in prominent and known channels.
BANG-BANG!
You see, silly reader, there is no way that the starting public keys could be wrong because they’ve been published on the Hedera website and in prominent channels.
Vitalik, why didn’t you think of doing that? Why did you feel you had to go and write boo-hoo posts about how hard it is to get acceptance for taking trusted short-cuts when designing a technology that was supposed to be trustless?
(Actually Vitalik did think of doing this and that’s how Ethereum will move from Proof-of-Work to Proof-of-Stake).
P.S. Vitalik, why don’t you just spin up a few nodes I can query 10,000 times per second about transactions you’ve supposedly confirmed? That way Ethereum would have the same TPS as a 3rd generation DLT like Hedera Hashgraph.
Okay I get it. But let’s assume I check the starting keys like a billion times with different people. I don’t care if Bitcoin maximalists says this is insecure, it’s more than enough for me. Will Hashgraph be able to do 10,000+ TPS then?
Fine, I’ll assume that you got the correct starting keys. But that doesn’t ensure that the people in control of those public keys can’t create completely fake state proofs.
That’s not true. Hedera Hashgraph is “aBFT”. That’s the highest security standard a distributed consensus system can have.
Just because it is aBFT (Byzantine fault-tolerant under asynchrony) doesn’t mean that a majority of the Hedera nodes can’t produce invalid results if they want to. You still have to trust them not to do anything bad.
That’s not true. Hedera Hashgraph is Proof-of-Stake. The nodes would lose a shit-ton of money if they gave fake state proofs.
Okay, so we need to roll back the tape a bit. Those “state proofs” that prove a part of the hashgraph state? Those aren’t really proofs. They’re more like commitments. It means that the Hedera nodes have committed (can’t claim they didn’t sign it) to a Merkle root (the state), but it doesn’t actually prove that the state is valid.
Now, the way it works in a real Proof-of-Stake chain, is that if the validator nodes sign invalid states or multiple different states with the same block/sequence number, you get to destroy their stake by broadcasting the fake proof they sent you.
Not with Hedera Hashgraph!
In the Hedera system, the nodes haven’t actually locked up any stake that you can destroy. So if this happens, you’ll have to go to a court!
Scalability through courts
In Bitcoin and Ethereum, we have what is called “Layer 2″ scaling solutions. In these “upper layers”, the inefficiencies of the base-layer don’t exist anymore. Up in these layers, you can do thousands, tens of thousands or even millions of transactions per second. And if something goes wrong up in these layers or someone tries to cheat you, you use the base-layer as the “court”, who then acts as an arbiter of what really happened.

This can mean that the person who tried to steal something will lose more money than they tried to steal, or that the base-layer just rejects the theft and gives the money to the right person instead. These “sentences” are executed with cryptographic certainty as long as the base-layer is still functional. If you see some wrong-doing, you can dispute it, and if you have the cryptographic proof of malfeasance, the court will sentence in your favor. Every single time.
And in order to keep this what is really a magical and powerful beast of a base-layer functional under all circumstances and accessible to everyone, we throttle the amount of data it needs to process. That’s the whole shebang of modern cryptocurrency scaling efforts explained. Now you know it.
And Hedera Hashgraph, the 3rd generation DLT that achieves 10,000+ TPS, is also scaling through the use of courts.
But it’s using old, traditional courts. Where you have to hire a lawyer. Because that’s the only thing you can do if you get screwed in this system.
But don’t take it from me, take it from Leemon himself (timestamp at 23:20).
Interesting indeed!
Well, what else can I say at this point?
Lawyer up?
And good luck, probably.

That’s all folks, time for me to get back to Twitter fights.